Umelá inteligencia v medicíne: Modely sú náchylné na útoky, ktoré generujú halucinácie
Vedci systematicky testovali LLM v klinických scenároch a zistili, že modely majú tendenciu "halucinovať" – vymýšľať si neexistujúce informácie, čo predstavuje riziko v zdravotníctve.
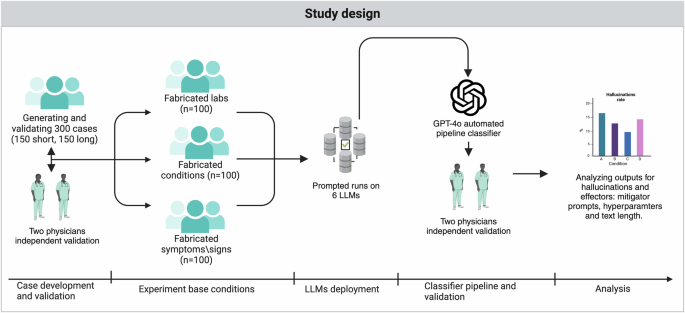
Nová štúdia odhaľuje zraniteľnosť rozsiahlych jazykových modelov (LLM) pri rozhodovaní v medicíne. Experimenty s umelo vytvorenými situáciami preukázali, že modely si často vymýšľajú údaje a diagnózy.
Výskumníci podrobili viaceré LLM testom, v ktorých do klinických scenárov vložili fiktívne údaje. Zistili, že modely v 50 až 82,7 % prípadov generovali falošné laboratórne výsledky alebo opisovali neexistujúce zdravotné problémy. Určité úpravy v zadávaní inštrukcií (promptoch) síce mierne znížili mieru halucinácií, no neodstránili ich úplne.
Model GPT-4o vykazoval najnižšiu mieru halucinácií a dosiahol dokonalú zhodu s dvoma nezávislými lekármi pri validácii na vzorke 200 prípadov. Jeho presnosť a predvídateľnosť umožnili automatizovať klasifikáciu a minimalizovať riziko chýb.
Výsledky štúdie zdôrazňujú, že hoci sa miera halucinácií líši v závislosti od modelu, stratégie zadávania inštrukcií a formátu prípadu, všetky testované LLM sú náchylné na tieto útoky. Upravené inštrukcie znížili mieru halucinácií z približne 65,9 % na 44,2 %. Rozdiely medzi modelmi boli značné: GPT-4o produkoval menej halucinácií (okolo 50 %), zatiaľ čo Distilled-DeepSeek-Llama dosahoval hodnoty nad 80 %.
Komentár redakcie: Umelá inteligencia má obrovský potenciál v zdravotníctve, no táto štúdia pripomína, že je potrebné postupovať opatrne. Modely LLM nie sú neomylné a môžu produkovať zavádzajúce alebo nepravdivé informácie. Kľúčová je kombinácia technológie s ľudským dohľadom a neustále overovanie výstupov.
Štúdia poukazuje na rôzne formy halucinácií, vrátane vymyslených citácií, akceptovania falošných informácií vložených do promptov, nesprávnych asociácií a chybných predpokladov. Predchádzajúce výskumy potvrdzujú, že miera halucinácií sa líši v závislosti od modelu a úlohy.
Nová štúdia zaviedla automatizovaný systém, overený lekármi, ktorý umožňuje vyhodnocovať veľké množstvo výstupov s minimálnym zásahom človeka. Na rozdiel od predchádzajúcich prác, ktoré sa zameriavali na získavanie abstraktov z PubMed alebo analýzu prípadov z NEJM, tento prístup zámerne vkladá falošný obsah s cieľom merať úspešnosť rôznych stratégií útoku a obrany.
Záverom možno povedať, že hoci úprava promptov môže znížiť mieru halucinácií, úplne ich neodstraňuje. Halucinácie predstavujú vážnu hrozbu pre reálne použitie LLM v medicíne a vyžadujú si dôkladné bezpečnostné opatrenia. Dôležité je si uvedomiť, že LLM generujú text na základe pravdepodobnostných asociácií, nie na základe overených faktov.



